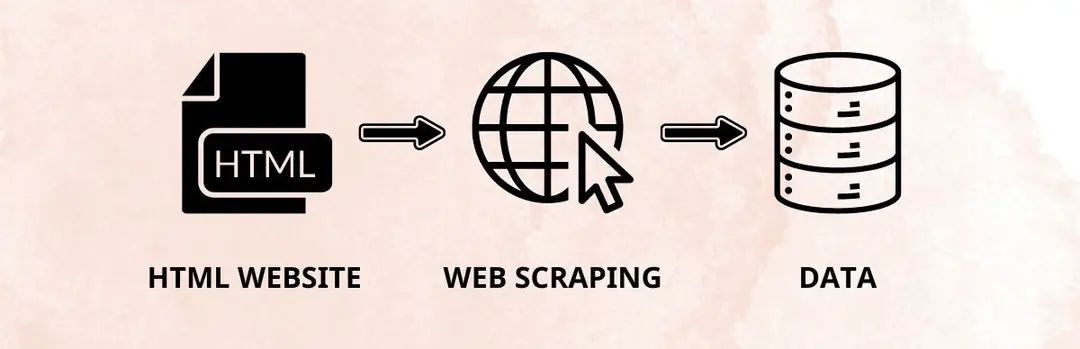
Web Scraping là một kỹ thuật tự động thu nhật dữ liệu từ các trang web, đóng vai trò quan trọng trong việc truy xuất thông tin trong thồi đại số hóa. Đây là một công cụ mạnh mẽ giúp doanh nghiệp và tổ chức khai thác dữ liệu nhanh chóng và chính xác. Trong bài viết dưới đây, hãy cùng thiết kế website tại Đà Nẵng tìm hiểu Web Scraping là gì và những ứng dụng thực tiễn của nó.
Web Scraping là gì?
Web Scraping là một kỹ thuật dùng để tự động thu thập dữ liệu từ các trang web và chuyển đổi dữ liệu đó thành các định dạng khác, như bảng tính (CSV, XLSX) hoặc JSON. Ngoài tên gọi Web Scraping, kỹ thuật này còn được biết đến với các cách gọi khác như Site Scraping hay Data Scraping.
Mục tiêu chính của kỹ thuật này là thu thập thông tin cần thiết từ các website để phục vụ cho nhiều mục đích khác nhau. Ví dụ các ứng dụng so sánh giá vé máy bay sử dụng kỹ thuật này để cung cấp cho người dùng thông tin về các chuyến bay có giá rẻ, thời gian bay nhanh nhất,…
Web Scraping có thể được thực hiện thủ công bởi con người hoặc tự động bằng cách sử dụng các chương trình máy tính gọi là web crawlers. Các ứng dụng của kỹ thuật này rất đa dạng, từ nghiên cứu thị trường, theo dõi giá cả đến phân tích dữ liệu lớn và chỉ bị giới hạn bởi sự sáng tạo của con người. Việc sử dụng kỹ thuật này giúp tiết kiệm thời gian và công sức so với việc thu thập dữ liệu thủ công, đồng thời cho phép xử lý một lượng lớn dữ liệu một cách hiệu quả.

Một số loại Web Scraping
Web Scraping có thể được thực hiện bằng nhiều phương pháp và kỹ thuật khác nhau, mỗi loại đều có những ưu điểm và ứng dụng riêng. Dưới đây là một số phương pháp phổ biến nhất:
- Phân tích HTML: Phương pháp này sử dụng các thư viện để phân tích cấu trúc HTML của website. Các công cụ này giúp bạn trích xuất dữ liệu dựa trên các thẻ HTML, lớp và id. Qua đó cho phép bạn dễ dàng lấy được thông tin cụ thể từ một website.
- Sử dụng API: Một số website cung cấp API (Giao diện lập trình ứng dụng) để truy cập dữ liệu một cách có cấu trúc. Sử dụng API là cách hiệu quả và dễ dàng để thu thập dữ liệu mà không cần phải xử lý HTML trực tiếp như Web Scraping truyền thống.
- Sử dụng Selenium: Selenium là một công cụ tự động hóa trình duyệt web, cho phép bạn tương tác với trang web như một người dùng thực sự. Bằng cách mô phỏng các hành động như nhấp chuột và điền form, Selenium giúp trích xuất dữ liệu từ các trang web động hoặc có nội dung tải lên từ JavaScript – một ngôn ngữ lập trình phổ biến.
- Sử dụng các Framework Scraping: Các framework như Scrapy, Puppeteer và Cheerio được thiết kế để phát triển và thực hiện các tác vụ liên quan đến web scraping. Chúng cung cấp các tiện ích giúp thu thập dữ liệu một cách tự động, liên tục và ổn định, giúp người dùng dễ dàng quản lý và lập lịch trình cho các quy trình scraping phức tạp.
Cách hoạt động của Web Scraping là gì?
Web scraper là một công cụ giúp tự động tải xuống và phân tích cấu trúc của các trang web để trích xuất dữ liệu theo yêu cầu của người dùng. Dưới đây là quy trình cơ bản mà kỹ thuật này thường thực hiện:
- Lập kế hoạch và xác định dữ liệu cần thu thập: Người dùng xác định rõ những thông tin mà họ muốn lấy từ trang web, chẳng hạn như giá sản phẩm, mô tả sản phẩm, hoặc thông tin liên hệ.
- Tải trang web: Web scraper truy cập và tải nội dung của trang web mục tiêu thông qua địa chỉ URL được cung cấp.
- Phân tích HTML: Sau khi tải trang, web scraper phân tích cấu trúc HTML để tìm kiếm các thành phần chứa dữ liệu cần thiết, dựa trên các thẻ, lớp và id.
- Trích xuất dữ liệu: Dữ liệu được trích xuất từ trang web theo cấu trúc đã xác định, sử dụng các kỹ thuật như truy vấn XPath, CSS selectors, hoặc regex.
- Lưu trữ dữ liệu: Dữ liệu thu thập được lưu trữ trong cơ sở dữ liệu, tệp tin, hoặc các hệ thống lưu trữ khác để sử dụng cho các mục đích phân tích hoặc hiển thị sau này.
Web scraper có thể tự động hóa quy trình này để thu thập dữ liệu từ nhiều trang web khác nhau một cách hiệu quả và liên tục. Tuy nhiên, khi sử dụng web scraper, cần đảm bảo tuân thủ các quy định về bản quyền, chính sách sử dụng của trang web và các quy định pháp luật liên quan đến việc thu thập dữ liệu từ internet.
Ứng dụng Web Scraping
Web scraping đã trở thành một công cụ mạnh mẽ và đa dạng, ứng dụng trong nhiều lĩnh vực khác nhau từ tìm kiếm thông tin, nghiên cứu thị trường, đến theo dõi giá cả và tin tức. Dưới đây là những cách mà web scraping đang được sử dụng hiệu quả:
Công cụ tìm kiếm
Rất nhiều người có thể bất ngờ khi biết rằng Google là một trong những web scraper lớn nhất trên internet. Các công cụ tìm kiếm như Google, Bing và Yahoo là những ví dụ điển hình của việc sử dụng web scraping. Bot crawler của các công cụ tìm kiếm liên tục trích xuất nội dung từ các trang web để sắp xếp và xếp hạng các trang đó. Dữ liệu thu thập được đưa vào thuật toán phức tạp để đánh giá các trang web theo tiêu chí riêng của mỗi công cụ tìm kiếm.
Nghiên cứu thị trường
Web scraping là công cụ đắc lực cho các công ty trong việc nghiên cứu thị trường. Công việc này yêu cầu thu thập lượng dữ liệu khổng lồ từ nhiều nguồn khác nhau. Các bot crawler sẽ trích xuất thông tin liên quan đến các khía cạnh cần nghiên cứu, tổng hợp lại để tạo thành một cơ sở dữ liệu hoàn chỉnh.
Từ dữ liệu này doanh nghiệp có thể phân tích, xác định xu hướng thị trường và dự đoán sự chuyển dịch trong tương lai. Ngoài ra, web scraping còn được dùng để nghiên cứu customer insights – tâm lý và hành vi tiêu dùng của khách hàng bằng cách trích xuất các cuộc hội thoại xã hội để làm dữ liệu phân tích.
Theo dõi giá cả
Web scraping được sử dụng rộng rãi trong các công cụ theo dõi và so sánh giá cả trên thị trường. Người tiêu dùng là khách hàng trực tiếp của các ứng dụng so sánh giá, chẳng hạn như giá vé máy bay, xe buýt, phòng khách sạn hay thực phẩm. Đối với các nhà đầu tư, web scraping giúp theo dõi giá cổ phiếu, bất động sản và tiền ảo (cryptocurrency). Ngoài ra, các thương hiệu và website bán hàng cũng dùng web scraping để thu thập thông tin về giá cả của đối thủ, từ đó điều chỉnh chiến lược giá của mình để cạnh tranh tốt hơn.
Website tổng hợp tin tức
Trong khi lướt web, bạn có thể bắt gặp những trang web tổng hợp tin tức không phải là các tờ báo chính thức. Đây là các cổng thông tin cung cấp lượng tin tức đa dạng hơn so với một tờ báo đơn lẻ. Các cổng thông tin có thể là website, ứng dụng di động hoặc ứng dụng đọc tin trên trang mới của trình duyệt web. Chúng hoạt động bằng cách crawl bài viết từ nhiều nguồn khác nhau trước khi hiển thị cho độc giả. Các website tổng hợp tin tức là một trong những ứng dụng phổ biến nhất của web scraping hiện nay.
Mặt trái của Web Scraping
Web scraping có nhiều ứng dụng hữu ích, nhưng cũng có thể bị lạm dụng cho mục đích không hợp pháp. Pháp luật hiện chưa quy định rõ về web scraping, nhưng việc dùng nó để đạt lợi thế cạnh tranh không công bằng là không được chấp nhận. Ví dụ, một số website sao chép nội dung từ đối thủ hoặc điều chỉnh giá sản phẩm để giành lợi thế phi pháp. Hacker cũng có thể sử dụng Web Scraping để đánh cắp dữ liệu và khai thác lỗ hổng bảo mật, gây lo ngại về an ninh mạng.

Để bảo vệ website của bạn khỏi việc trích xuất dữ liệu trái phép, hãy thực hiện một số biện pháp sau:
- Sử dụng công cụ để phân biệt giữa người và bot.
- Chú ý đến tài khoản mới không mua sắm nhưng hoạt động nhiều.
- Yêu cầu xác nhận qua các điều khoản, quy tắc hoặc captcha.
- Cập nhật công nghệ bảo mật và bot protection mới nhất.
Web Scraping là công cụ mạnh mẽ giúp thu thập dữ liệu từ các trang web một cách hiệu quả. Tuy nhiên, cần sử dụng kỹ thuật này một cách hợp pháp và đạo đức để tránh vi phạm quy định và vấn đề bảo mật. Khi áp dụng đúng cách, đây sẽ là một công cụ hữu ích trong việc cung cấp thông tin và hỗ trợ quyết định kinh doanh.